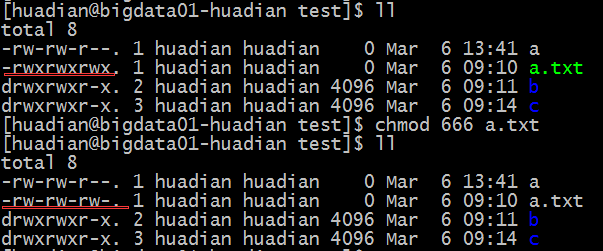
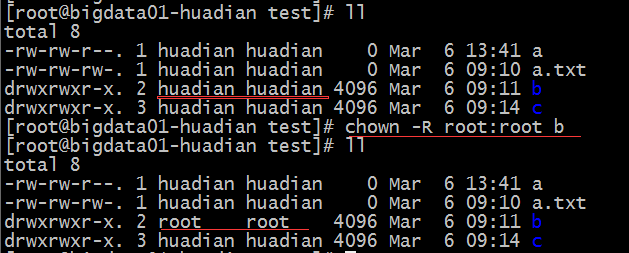
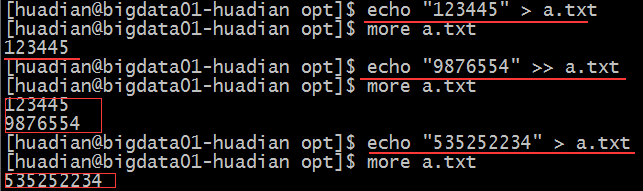
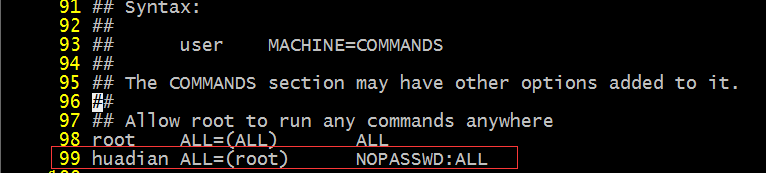
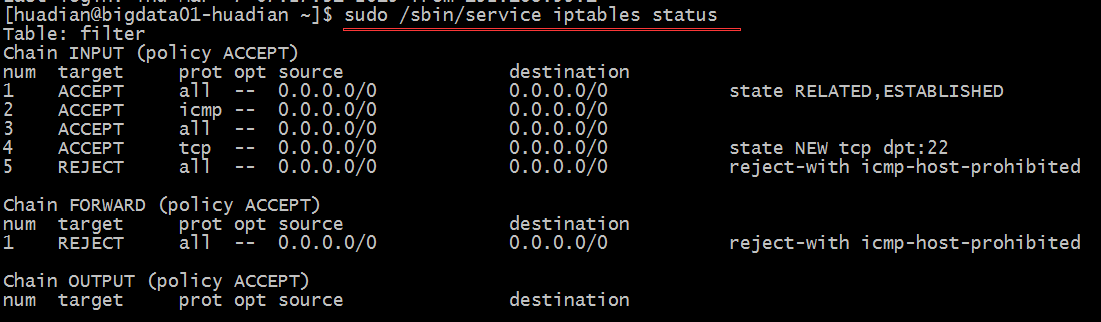
本文会记录一些显示器的常规参数含义,以及个人对显示器购买的建议。(持续更新)
面板
显示器面板有 IPS、TN、VA 三种类型。
- IPS屏: 面板较硬,用手指轻触屏幕,画面不会变形。IPS屏在色彩显示、可视角度等方面比TN面板好上不少,对于色彩的呈现范围与准确性也都有亮眼的表现,广视角是IPS面板的原生优势,不论哪个角度观看都不会产生色偏。但在响应时间上IPS屏比TN屏稍逊一筹,但得益于IPS屏出色的色彩表现,对于兼有办公娱乐多功能需求的普通游戏玩家,IPS屏仍然值得考虑。受制于IPS屏需要更多背光灯来提高亮度,功耗偏高的局限性,控制不好就会漏光是IPS屏的通病。不过专业的屏幕生产厂商在应对这个问题时通常有更规范的把控机制,更值得信赖。
- TN屏: 就是较早前常见的软屏,用手能按出水波纹,这是较早使用的LCD面板之一,目前也在大量使用,因为它的技术成熟,成本低。TN屏响应速度快,可以达到1ms的响应时间,不会出现残影。使用这种材质的屏幕通常用来作为职业电竞屏,通过快速响应,TN屏可无损呈现高速变化的场景细节。相对地,TN面板的缺陷也很明显,输出灰阶少,原生只有6bit色彩,画面色彩偏白、可视角度小,显示效果一般,通过不同角度观看会出现偏色和亮度差别。
- VA屏: VA类面板也属于软屏,只要用手指轻触面板,显现梅花纹的是VA面板,出现水波纹的则是TN面板。VA屏的特点是宽容度和对比度都更高,可达到3000:1的高对比度,画面中黑色和白色都更加纯净,且不会出现漏光等问题。VA面板的缺陷主要体现在响应时间方面,好在现在VA面板的响应时间已经大幅改善,可以低至6ms内,足够正常使用。
面板选购建议
普通办公:IPS、VA
游戏玩家:IPS>VA>TN
分辨率/尺寸
- 分辨率 目前主流的有1080P、2K、4K。分辨率越高画面就越细腻。
- 屏幕尺寸 有23.8-34寸,甚至更大。大屏幕最好选择2k/4k的分辨率,因为屏幕大而分辨率低的话会出现字体发虚、叠影等问题(本人踩过坑)
23寸选择:1080P
27寸选择:2K>1080P
34寸选择:4K>2K
刷新率
指的是每秒刷新画面的次数,刷新率越高,画面的稳定性越好。一般常见的是60~80Hz、144Hz、244Hz。办公+看视频用的话,60Hz也够了。
输入接口
老款显示屏都是VGA为主,现在新款的显示器是HDMI和DP。
显示器
本人目前也只使用过1000~1500左右的显示器,就推荐几款个人觉得还不错的千元显示器吧
1000元左右
明基BL2480T
- 特性:内置音响、旋转升降底座、TUV爱眼认证、四边微边框
- 尺寸/分辨率:23.5~24寸/1080p
- 刷新率:60Hz
- 面板:IPS
- 使用感受:目前个人家用办公娱乐使用,用了大概两年多,感觉足以满足日常写代码、看文档、看视频之类的需求。
- 京东链接:https://item.jd.com/8358211.html
戴尔P2422H
- 特性:旋转升降底座
- 尺寸/分辨率:23.5~24寸/1080p
- 刷新率:60Hz
- 面板:IPS
- 使用感受:上一家公司配的戴尔的差不多型号的电脑,能满足日常写代码、看文档、看视频之类的需求,就是特性不多,感觉戴尔的牌子有点溢价。
- 京东链接:https://item.jd.com/1604149839.html
飞利浦275S9DRL
- 特性:旋转升降底座
- 尺寸/分辨率:27寸/2k
- 刷新率:75Hz
- 面板:VA
- 使用感受:没用过,看参数感觉可以,颜值也好看,性价比也ok。
- 京东链接:https://item.jd.com/1604149839.html
优派(ViewSonic)VX2780-2K-HD
- 特性:节能认证,旋转升降底座
- 尺寸/分辨率:27寸/2k
- 刷新率:60Hz
- 面板:IPS
- 使用感受:目前公司在用的,能满足日常写代码、看文档、看视频之类的需求,2k屏相比1080p文字细腻度更好点,其他也没有太多特性,中规中矩吧。
- 京东链接:https://item.jd.com/100010568866.html
总结
- 大屏幕(例如27寸)就选择2k或4k分辨率,小屏幕24寸左右,就选择1080p
- 旋转可升降的特性个人认为对于办公党来说比较重要,方便调节到一个让颈椎比较舒适的位置,不然底部只能垫书了。其次关注有无 TUV爱眼认证,关系到长时间看屏幕会不会眼睛发酸。